
Hello everyone,
I want to introduce you today to a small project I’ve been working on recently. It’s called Jellyfin Audio Language Tagger and it helps automatically tag movies in your Jellyfin library with language labels.
Why do this?
I had the problem that I couldn’t easily filter my Jellyfin library by audio language. Normally, I watch movies in English, but when I’m with the family, I want to see only those movies that have German audio. That’s why I wrote this script, which searches the file name, folder name, and the titles of the embedded audio tracks. If it finds any hints of the German language, it appends a tag to the movie.nfo file. These tags then appear in Jellyfin’s filtering options.
Of course, one could—and really should—consistently name their movie collection from the start. That would make tagging much simpler, but over the years I wasn’t quite that diligent.
How it works
The script recursively goes through your media folders and uses ffprobe to analyze the movies’ audio tracks. If one of the search patterns is found (for example, “German”, “Deutsch”, “DE” or “De “), one or more tags (currently “German” and “Deutsch”) are added to the corresponding movie.nfo file (always located in the same folder as the media).
Where can you find the script?
What you need to consider
- Access rights:
Jellyfin needs the proper access rights to your media folders to read and use the movie.nfo files.
- Jellyfin settings:
Make sure your Jellyfin library is configured to store metadata in NFO files. In the library settings in the admin dashboard.
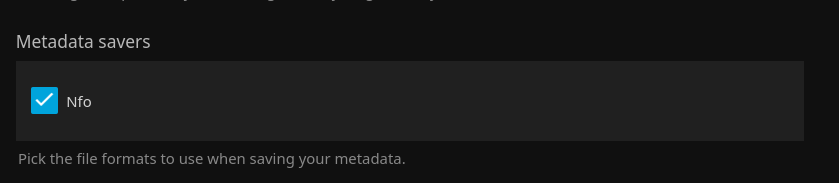
Secondly via the Jellyfin homepage -> your library -> “Edit Metadata”, uncheck the checkbox for “Tags”
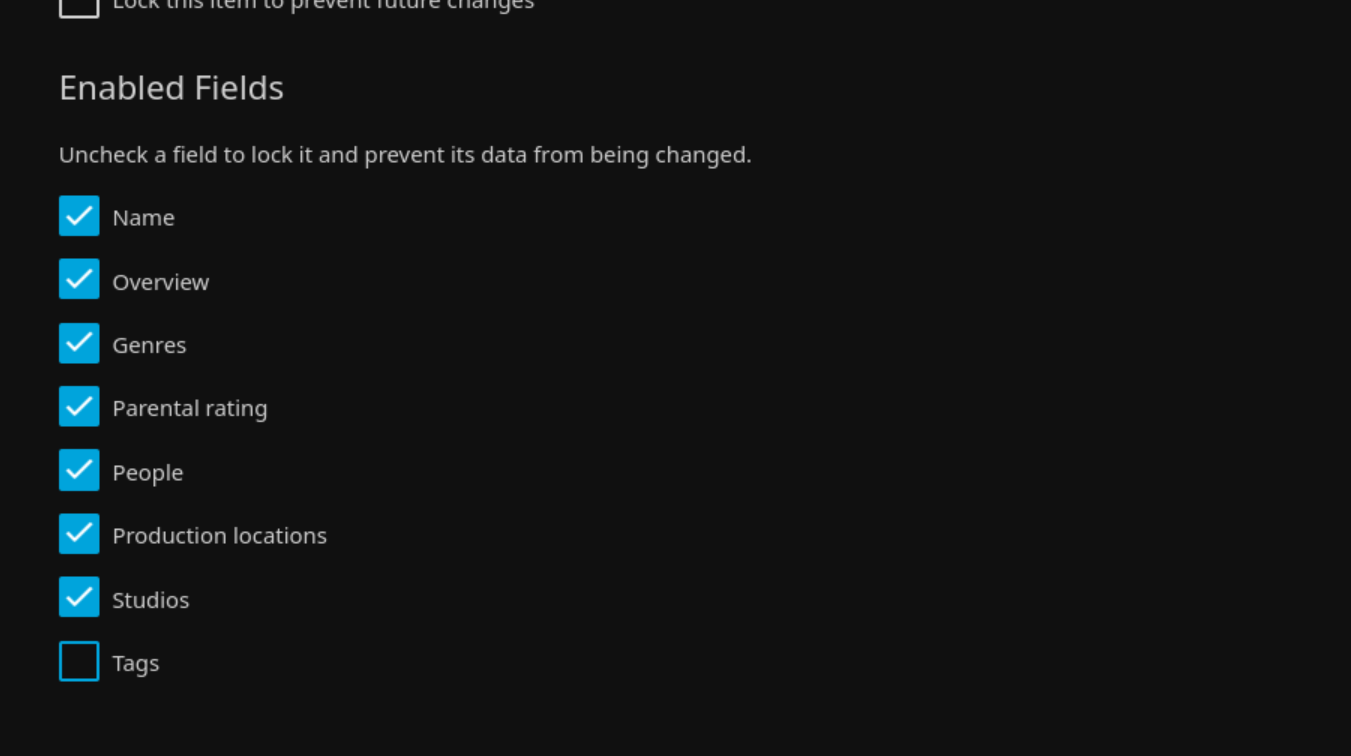
- Updating metadata:
After running the script, you need to refresh the metadata in Jellyfin. Use the three-dot menu in your library to select “Refresh metadata” and then “Scan for new and updated files” so the new tags are picked up.
First impressions and feedback
The script has personally helped me a lot to filter my movies by language. It currently supports only German but can be easily extended to recognize other languages. I welcome any feedback, suggestions for improvement, or alternative ideas on how to solve this problem. Perhaps you even know of a better, integrated solution for language filtering in Jellyfin.
